Can anyone help me with the solution of this problem? https://www.codechef.com/QUCO2018/problems/BEERUS/
Thanks in advance :)
Can anyone help me with the solution of this problem? https://www.codechef.com/QUCO2018/problems/BEERUS/
Thanks in advance :)
Contest
Practice
Author:Amit Kumar Pandey
Editorialist:Amit Kumar Pandey
SIMPLE
Maths
Ironman wants to build his new core. For that, he inputs three random number x, y and z in Jarvis. Help Jarvis determine whether those three numbers are taken as sides form the isosceles triangle or not.
A triangle is a 3-sided polygon.
We are given the length of three sides.
The condition for forming the triangle is the the sum of the two side of triangle must be greater than third side. If this condition satisfies then we have to find whether triangle is equilateral, isosceles or scalene triangle.
1. If all sides of the triangle are equal then it is equilateral.
2. If two sides are equals then the triangle is isosceles. If we find any isosceles triangle then we have to add one to counter variable because we have to print the total number of the isosceles triangle in the output.
3. else the triangle is scalene.
If the property of triangle doesn't get satisfied then we have to print "not triangle".
Author's solution can be found here.
Editorialist's solution can be found here.
Author:Jitender
Tester:Misha Chorniy
Editorialist:Bhuvnesh Jain
EASY-MEDIUM
Tries, Offline querying
You a given $N$ strings and $Q$ queries. For each query, given $R$ and string $P$, you need to find the lexicographically smallest string which has the largest common prefix with $S$.
A simple brute force which checks each string from index $1$ to $R$ and stores the answer at each step will suffice. Below is a pseudo-code for it:
def find_max_prefix_match(string a, string b):
ans = 0
for i in [0, len(a), len(b) - 1]:
if a[i] == b[i]:
ans += 1
else:
break
return ans
def solve_query(index R, string P):
ans = ""
prefix = 0
for i in [1, n]:
if find_max_prefix_match(S[i], P) > prefix:
prefix = find_max_prefix_match(S[i], P)
ans = S[i]
else if find_max_prefix_match(S[i], P) == prefix:
ans = min(ans, S[i])
return ans
The complexity of the above approach is $O(N * Q * 10)$ in the worst case as the maximum size of the string can be at most 10.
The first idea which comes whenever you see string problems deal with prefixes if using tries or hashing. In this problem too, we will use trie for solving the problem. In case you don't know about it, you can read it here.
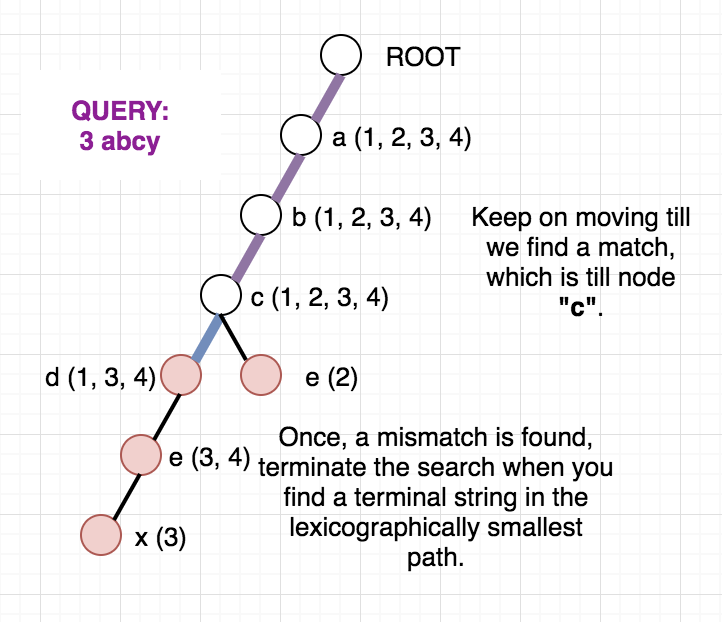
Let us first try to understand how to find the lexicographically smallest string with largest common prefix with $P$. Assume we have the trie of all the strings build with us. We just start traversing the Trie from the root, one level at a time. Say we are at level $i$, we will try to greedily go to the node whose character matches with our current character, $P[i]$. This will help us to maximise the longest common prefix. The moment we find a mismatch, i.e. a node with current character doesn't exist, we will try to now greedily find the lexicographically find the smallest string. For this, we just keep on traversing down the left-most node in the trie till a complete work is found.
But the above approach works when $R = N$ in all queries as without it we can't identify whether the string we are traversing lies in the required range of the query or not.
There are 2 different approaches to the full solution, Online solution and Offline solution.
The problems where we can easily solve a problem given a full array but need to query for a prefix of the array can be easily handled using offline queries. The idea is as follows:
We first sort the queries based on the index of the array given. We now build out data structure (here trie), incrementally. Say the data structure is built using all the first $i$ elements, we now answer every query which has an index as $i$ in the query.
The pseudo-code for it is below:
queries = []
for i in [1, q]:
r, p = input()
queries.push((r, p, i))
queries.sort()
cur_index = 0
for (r, p, i) in queries:
while (cur_index <= r):
insert_element_to_ds_trie
cur_index += 1
ans[i] = query_from_ds_trie(S) //parameter r is not required
for i in [1, q]:
print ans[i]
For more details, you can refer to the author's or tester's solution below.
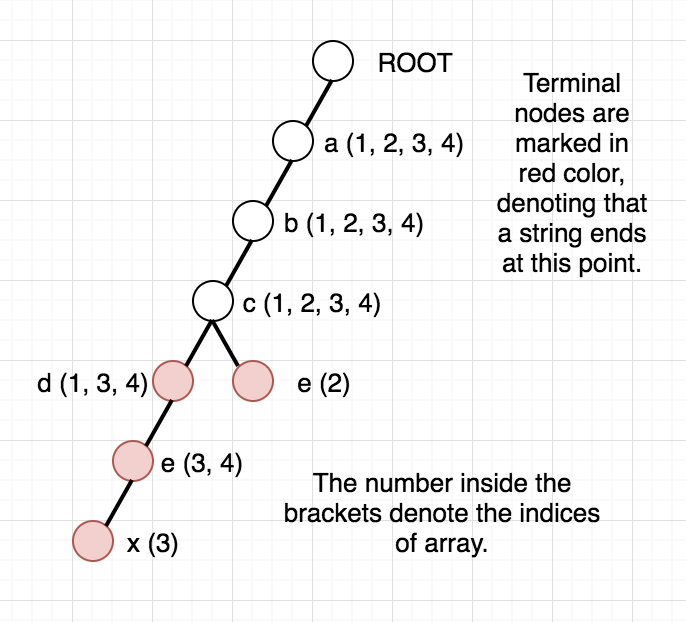
The idea is simple. With every node in the trie, we keep a vector of indices which it is a part of. Using this vector we can easily decide whether the string we are traversing lies within our required range or not. But before discussing the full solution, we need to be sure that this will fit into memory limits because seeing it in a naive manner seems to consume quadratic memory as each node can have a vector of length $N$.
To prove that the above-modified trie also uses linear memory in order of sum of the length of strings, we see that each index appears in any vector of a node in trie as many characters are there in the string. So, out trie just uses twice the memory that the normal trie (the one in author or tester solution) uses.
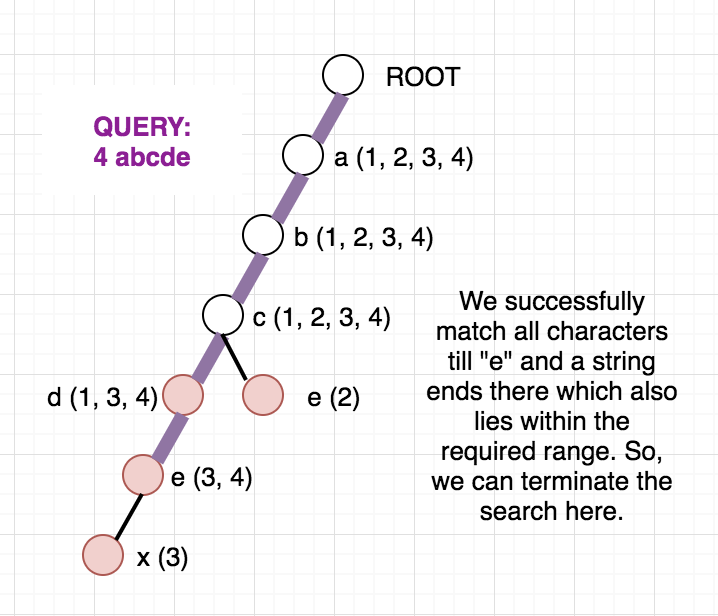
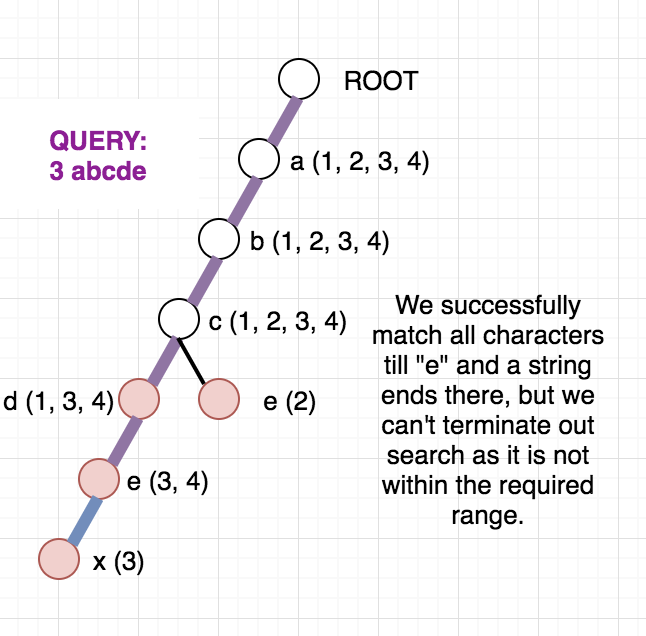
Once, the above modified Trie is built, we can answer our queries easily. Since the strings are added incrementally, we are sure that the vector containing the indices will always be in sorted order. To check whether any string at a given node lies in modified range, we can use binary search. But, we can be clever here too, as the binary search will be an overkill. Since the range we want is always a prefix of the array we can just check the first element of the vector and decide whether any string lies in the required range or not. To get a clear picture of the above, you can see the below picture of the trie build from the sample case in the problem. It also contains how the answer to different queries are arrived at.
Once, you are clear with the above idea, you can see the editorialist implementation below for help.
Feel free to share your approach, if it was somewhat different.
$O(Q\log{Q} + \text{Sum of length of strings} * \text{ALPHABET})$ for offline solution
$O(\text{Sum of length of strings} * \text{ALPHABET})$ for online solution
where $\text{ALPHABET} = $ number of distinct english character (26 for this problem).
$O(\text{Sum of length of strings})$
Author's solution can be found here.
Editorialist's solution can be found here.
Contest
Practice
Author: Mrinal Sinha
Editorialist: Mrinal Sinha
Tester:Amit Kumar Pandey
EASY
Math
Starlord is stuck in space on his way back after a successful mission when his spacecraft crashed. He now has to go jumping from asteroid to asteroid to get to a nearby space camp. The asteroids are in such an order that their lengths increase to a certain extent as he jumps to the next asteroid. The series of the lengths of the asteroids is given below. For a given asteroid, you have to determine whether it comes in his path or not. Series: 44, 120, 304, 736
The series given here is an Arithmetico-Geometrico Series with numbers written as 11 * 4, 15*8, 19*16 and 23*32 respectively. Thus the first term of the A.P is 11 with common difference 4 whereas the first term of G.P is 4 with common ratio 2. With the help of above values we can determine the previous positive values which will be 7*2 =14 and 3*1 = 3.
Thus the general formula for the above expression is (a+(n-1)*d)*(b*pow(r,n-1)), where ‘a’ is the 1st term of the A.P (which is 3), ‘d’ is the common difference of the A.P (which is 4), ‘b’ is the 1st term of G.P (which is 1), ‘r’ is the common ratio of the G.P (which is 2) and ‘n’ is the nth term of the series.
Thus initialize n with 1 and calculate the value of above expression.
Thus initialize n with 1 and calculate the value of above expression.
If the value is equal to the given number, then print “YES”.
If the value is greater than the given number ,then print “NO”.
*If the value is less than the given number, then increment n by 1 and again check whether the value of the expression is greater than or equal to the given number. Do this step until the 1st or 2nd step is satisfied.
Author's solution can be found here.
Editorialist's solution can be found here.
Tester's solution can be found here.
Hello everyone,
I like Programming very much but due to some reasons, I am not able to perform well. Most of the time I get "wrong answer" even if it seems to be correct(may be due to it isn't working for even 1 test case). So please tell me some tricks and tips which would help me. Such as how to test your program, must know algorithms, the way you follow while coding or anything else.
Thank You in advance.
Tips for Optimizing C/C++ Code
1.Code for correctness first, then optimize!
This does not mean write a fully functional ray tracer for 8 weeks, then optimize for 8 weeks!
Perform optimizations on your ray tracer in multiple steps.
Write for correctness, then if you know the function will be called frequently, perform obvious optimizations.
Then profile to find bottlenecks, and remove the bottlenecks (by optimization or by improving the algorithm). Often improving the algorithm drastically changes the bottleneck – perhaps to a function you might not expect. This is a good reason to perform obvious optimizations on all functions you know will be frequently used.
2.People I know who write very efficient code say they spend at least twice as long optimizing code as they spend writing code.
3.Jumps/branches are expensive. Minimize their use whenever possible.
Function calls require two jumps, in addition to stack memory manipulation.
Prefer iteration over recursion.
Use inline functions for short functions to eliminate function overhead.
Move loops inside function calls (e.g., change for(i=0;i<100;i++) DoSomething(); into DoSomething() { for(i=0;i<100;i++) { ... } } ).
Long if...else if...else if...else if... chains require lots of jumps for cases near the end of the chain (in addition to testing each condition). If possible, convert to a switch statement, which the compiler sometimes optimizes into a table lookup with a single jump. If a switch statement is not possible, put the most common clauses at the beginning of the if chain.
4.Avoid/reduce the number of local variables.
Local variables are normally stored on the stack. However if there are few enough, they can instead be stored in registers. In this case, the function not only gets the benefit of the faster memory access of data stored in registers, but the function avoids the overhead of setting up a stack frame.
(Do not, however, switch wholesale to global variables!)
5.Reduce the number of function parameters.
6.If you do not need a return value from a function, do not define one.
7.Try to avoid casting where possible.
Integer and floating point instructions often operate on different registers, so a cast requires a copy.
Shorter integer types (char and short) still require the use of a full-sized register, and they need to be padded to 32/64-bits and then converted back to the smaller size before storing back in memory. (However, this cost must be weighed against the additional memory cost of a larger data type.)
8.Use shift operations >> and << instead of integer multiplication and division, where possible.
9.Simplify your equations on paper!
In many equations, terms cancel out... either always or in some special cases.
The compiler cannot find these simplifications, but you can. Eliminating a few expensive operations inside an inner loop can speed your program more than days working on other parts.
10.Consider ways of rephrasing your math to eliminate expensive operations.
If you perform a loop, make sure computations that do not change between iterations are pulled out of the loop.
Consider if you can compute values in a loop incrementally (instead of computing from scratch each iteration).
11.Avoid unnecessary data initialization.
1216. For most classes, use the operators += , -= , *= , and /= , instead of the operators + , - , * , and / .
The simple operations need to create an unnamed, temporary intermediate object.
For instance: Vector v = Vector(1,0,0) + Vector(0,1,0) + Vector(0,0,1); creates five unnamed, temporary Vectors: Vector(1,0,0), Vector(0,1,0), Vector(0,0,1), Vector(1,0,0) + Vector(0,1,0), and Vector(1,0,0) + Vector(0,1,0) + Vector(0,0,1).
The slightly more verbose code: Vector v(1,0,0); v+= Vector(0,1,0); v+= Vector(0,0,1); only creates two temporary Vectors: Vector(0,1,0) and Vector(0,0,1). This saves 6 functions calls (3 constructors and 3 destructors).
13.For basic data types, use the operators + , - , * , and / instead of the operators += , -= , *= , and /= .
14.Delay declaring local variables.
Declaring object variable always involves a function call (to the constructor).
If a variable is only needed sometimes (e.g., inside an if statement) only declare when necessary, so the constructor is only called if the variable will be used.
15Avoid dynamic memory allocation during computation.
Dynamic memory is great for storing the scene and other data that does not change during computation.
However, on many (most) systems dynamic memory allocation requires the use of locks to control a access to the allocator. For multi-threaded applications that use dynamic memory, you may actually get a slowdown by adding additional processors, due to the wait to allocate and free memory!
Even for single threaded applications, allocating memory on the heap is more expensive than adding it on the stack. The operating system needs to perform some computation to find a memory block of the requisite size.
Hey,all
Can someone help me in finding the error in logic as my last case is not passing.
Any help would be appreciated.
My logic
I have taken two set one set will contain all the ingredients found on islands is it size comes out not equal to k then we will print sad.
If it's size becomes equal to k then we will check the size of other set is n if it is n it means we have taken ingredients from every islands so the size becomes n which is equal to no of islands so we will print all.
else we will print sad.
Can anyone help me out:
Author:Tianyi
Tester:Misha Chorniy
Editorialist:Bhuvnesh Jain
HARD
Flows, Minimum Cut
You are given a grid consisting of $0$(white), $1$(black) and $?$(unknown). You are required to convert $?$ to $0$ or $1$ such that the following cost is maximised:
$$\sum_{i=1}^{\mathrm{min}(N, M)} C_{B, i} \cdot B_i + C_{W, i} \cdot W_i\,.$$
where $B_i$ denotes the number of ways to select a black square of size $i$, $W_i$ denotes the number of ways to select a white square of size $i$ and $C_{B, i}$ and $C_{W, i}$ arrays is provided in input.
A simple brute force which converts each $?$ to $0$ or $1$ and calculates the cost of the board is sufficient to pass this subtask. The time complexity of the above approach is $O(2^{NM})$.
The constraints are small and since the problem is related with maximisation, it hints towards either dynamic programming or flows based solution generally. We will use minimum cut to solve this problem. In case you are not familiar with the topic or its usage in the problem, please you through this awesome video tutorial by Anudeep Nekkanti.
Now, using the ideas similar in the video, we design the below algorithm.
To understand why the above algorithm works, we will reason cutting of each edge in terms of minimum cuts and the rewards/penalties it provides.
It is sure that edges of weight INFINITY will never be considered in the minimum cut of the graph. So we consider the remaining 2 scenarios.
This image shows the scenario where the edge containing white node (source) and the node representing an optimistic white square of length $L$ is cut. This implies one of the $?$ in the square chose to convert to $1$ instead of $0$. This can happen for whatever reason, for example - It might to costlier to cut the corresponding black edges to which the $?$ node also connects (such a node will exist otherwise there will be no path from white i.e. source to black i.e. sink).
This case is similar to above case, just that instead one of the $?$ in the optimistic black square of length $L$ chose to convert to $0$ instead of $1$.
Thus the minimum cut in the above graph will contain edges which tell that the optimistic square which we considered for being white or black will not be actually white or black in the optimal selection because one of $?$ chose to convert to opposite colour. We must thus remove this minimum optimistic answer we added to "initial ans" to obtain the solution to the problem.
Let us now finally analyse the complexity of the above solution. For the worst case, the grid will only consist of $?$ as there are no edges coming out of $0$ or $1$ in the grid. Let $K = min(N, M)$. So there will be $N * M + (N - 1) * (M - 1) + \cdots + (N - K) * (M - K) = O(K^3)$ intermediate white and black nodes i.e. the ones connecting grid cells and also to the corresponding source or sink. For details of the proof, refer to this. The number of edges in the graph will be $O(K^4)$ as there can be maximum $O(L^2)$ edges from an intermediate node representing the square of length $L$. Using Dinic Algorithm which has the worst complexity of $O(V^2 * E)$, the overall complexity of the solution will be $O(K^{10})$ ~ $O({(N * M)}^3)$. The hidden constant factor is very low and Dinic's algorithm suffices to solve the problem.
Note that above solution using minimum cut also enables us to print one grid with required cost as well. The construction of such grid is simple. Just consider the edges from white (source) and black (sink) node to the intermediate nodes which are not part of the minimum cut. This means all the cells in the grid connected to it actually retained their preference to colour which was optimistically assigned before to them.
Once, you are clear with the above idea, you can see the editorialist implementation below for help. It also contains the part for printing a possible grid with the conversion of $?$ to $0$ or $1$.
Feel free to share your approach, if it was somewhat different.
$O({(N * M)}^3)$
$O({(N * M)}^3)$
Author's solution can be found here.
Editorialist's solution can be found here.
Author:Igor Barenblat
Tester:Misha Chorniy
Editorialist:Bhuvnesh Jain
MEDIUM-HARD
Dynamic Convex-Hull Trick, Heavy-Light Decomposition
You are given a tree with $N$ nodes. $M$ speedsters travel on the tree. The $i^{th}$ speedster starts at time $t_i$ from vertex $u_i$ and travels towards $v_i$ at a constant speed of $s_i$. For every vertex, we need to find the first time, any speedster visited it. In case, it was not visited by any speedster, report the answer as -1.
For simplicity, let us assume that the tree is rooted at node $1$ and the depth of all vertices from the root is calculated. The depth is basically the distance of the vertex from the root of the tree i.e. $1$.
Let us first write the equation for time taken by speedster $i$ reach a vertex $x$. If the vertex doesn't lie on the path from $u_i$ to $v_i$ then it is not visited by speedster $i$, or the time taken is INFINITY (a large constant). For all the other vertices on the directed path from $u_i$ to $v_i$, the time taken is given by:
$$\text{Time taken} = t_i + \frac{\text{Distance from vertex }u_i}{s_i}$$
$$\text{Distance between x and y} = \text{Depth[x]} + \text{Depth[y]} - 2 * \text{Depth[lca(x, y)]}$$
where $lca(x, y)$ is the lowest common ancestor of vertices $x$ and $y$.
We can now modify the equation for the time taken to reach any vertex on the path from $u_i$ to $v_i$ as follows:
Let the lowest common ancestor of $u_i$ and $v_i$ be $lca$. Calculate the final time at which we reach vertex $v_i$. Let us denote this by $t_f$. We now split the path from $u_i$ to $v_i$ into 2 parts: one from $u_i$ to $lca$ and from $lca$ to $v_i$. NIte that these paths are directed. The image below shows how to calculate the time at any vertex $x$ and $y$ on the 2 different paths.
From the above figure, for a node $x$ on path from $u_i$ to $lca$, the time to reach it is:
$$\text{Time taken to reach x} = t_i + \frac{(Depth[u] - Depth[x])}{s_i} = \big(t_i + \frac{Depth[u]}{s_i}\big) - \frac{1}{s_i} * Depth[x]$$
Similarly, for a node $y$ on path from $lca$ to $v_i$, the time to reach it is:
$$\text{Time taken to reach y} = t_f - \frac{(Depth[v] - Depth[y])}{s_i} = \big(t_f - \frac{Depth[v]}{s_i}\big) - \frac{1}{s_i} * Depth[y]$$
If we observe carefully, both the above equations look the form $Y = MX + C$, where the first bracket part is $C$, time to be calculated is $Y$, $\frac{1}{s_i}$ is the slope ($M$) and the depth of the node is $X$.
The problem asks us to find minimum time at which every node is visited by any speedster, and the above equations clearly show that time to reach it only depends on the depth of the node and pair $(constant, slope)$ which is known beforehand for every speedster. Thus, this indicates the final solution will use the Dynamic convex-hull trick (Dynamic variant as the slopes are not guaranteed to be in increasing/decreasing order). If you don't know about it or its use case, you can read it here
So, let us first try to solve a simple version of the problem where the tree is a bamboo(a straight path). This basically rules out the tree of the problem and reduces it to updates and queries of the following form on an array:
Update: Add a line $(M, C)$ denoting $Y = MX + C$ to every index in range $[l, r]$.
Query: Find the minimum value at any index $l$ for a given value of $X = w$.
We have range updates and point queries. So, we will use segment trees for the solution. In each node of the segment tree, we will keep the lines (represented by $(M, C)$) and for querying, we will just use the convex-hull trick to evaluate the minimum at node efficiently. Below is the pseudo-code for the segment-tree:
def init(t, i, j):
if i == j:
seg[t].clear() # remove all the lines
return
mid = (i+j)/2
init(2*t, i, mid)
init(2*t, mid+1, j)
def update(t, i, j, l, r, M, C):
if i > r or j < l:
return
if l <= i and j <= r:
# within required range
seg[t].add_line({M, C})
return
mid = (i+j)/2
update(2*t, i, mid, l, r, M, C)
update(2*t+1, mid+1, j, l, r, M, C)
def query(t, i, j, l, r, X):
if l <= i and j <= r:
return seg[t].evaluate_minimum(X)
mid = (i+j)/2
if i <= mid:
if j <= mid:
return query(2*t, i, mid, l, r, X)
else:
a = query(2*t, i, mid, l, r, X)
b = query(2*t+1, mid+1, j, l, r, X)
return min(a, b)
else:
return query(2*t+1, mid+1, j, l, r, X)
The time complexity of the above operations on segment tree is $O(\log{N} * \log{M})$ for both update and query. This is because each update and query will visit at most $O(\log{N})$ nodes and operation on every node (addition of a line or querying for minimum) is $O(\log{M})$. For a good reference code to the Dynamic convex hull, you can look up this.
Back to the tree problem. We see that we can easily handle queries on an array and the queries on the tree as basically those on a path. Voila, we can simply use Heavy light Decomposition or any other data structure you are suitable with (Euler Path or Centroid Decomposition). Thus, we efficiently solve the problem.
The overall time-complexity of the above approach using heavy-light decomposition will be $O({\log}^{2}{N} * \log{M})$ per update and query as it divides the path between the vertices $u$ and $v$ into $O(\log{N})$ path each of which is a straight path and can be solved using the segment tree mentioned above.
You can look at the author's implementation for more details.
Feel free to share your approach, if it was somewhat different.
$O((N + M) * {\log}^{2}{N} * \log{M})$
$O(N + M)$
Author's solution can be found here.
I'm not sure to class this as an editorial or whatever, but it's interesting. A well spent few hours digging into this.
I figured during the competition that VSN should have a closed form expression, a quadratic equation in something like 13 variables. It turns out that that is indeed true. After some mathematica magic I derived a “beautiful” formula that solved the problem. As mentioned in another question python3 has TLE problems with the binary search method, with the closed form solution python3 actually passes, albeit with a struggle: 18916971.
The formula in python form is
2*cy**2*dx*px + 2*cz**2*dx*px - 2*cx*cy*dy*px - 2*cx*cz*dz*px +
2*cy*dy*px**2 + 2*cz*dz*px**2 - 2*cx*cy*dx*py + 2*cx**2*dy*py +
2*cz**2*dy*py - 2*cy*cz*dz*py - 2*cy*dx*px*py - 2*cx*dy*px*py +
2*cx*dx*py**2 + 2*cz*dz*py**2 - 2*cx*cz*dx*pz - 2*cy*cz*dy*pz +
2*cx**2*dz*pz + 2*cy**2*dz*pz - 2*cz*dx*px*pz - 2*cx*dz*px*pz -
2*cz*dy*py*pz - 2*cy*dz*py*pz + 2*cx*dx*pz**2 + 2*cy*dy*pz**2 -
2*cy**2*dx*qx - 2*cz**2*dx*qx + 2*cx*cy*dy*qx + 2*cx*cz*dz*qx -
2*cy*dy*px*qx - 2*cz*dz*px*qx + 4*cy*dx*py*qx - 2*cx*dy*py*qx +
2*dy*px*py*qx - 2*dx*py**2*qx + 4*cz*dx*pz*qx - 2*cx*dz*pz*qx +
2*dz*px*pz*qx - 2*dx*pz**2*qx + 2*cx*cy*dx*qy - 2*cx**2*dy*qy -
2*cz**2*dy*qy + 2*cy*cz*dz*qy - 2*cy*dx*px*qy + 4*cx*dy*px*qy -
2*dy*px**2*qy - 2*cx*dx*py*qy - 2*cz*dz*py*qy + 2*dx*px*py*qy +
4*cz*dy*pz*qy - 2*cy*dz*pz*qy + 2*dz*py*pz*qy - 2*dy*pz**2*qy +
2*cx*cz*dx*qz + 2*cy*cz*dy*qz - 2*cx**2*dz*qz - 2*cy**2*dz*qz -
2*cz*dx*px*qz + 4*cx*dz*px*qz - 2*dz*px**2*qz - 2*cz*dy*py*qz +
4*cy*dz*py*qz - 2*dz*py**2*qz - 2*cx*dx*pz*qz - 2*cy*dy*pz*qz +
2*dx*px*pz*qz + 2*dy*py*pz*qz - 2*dx*px*r**2 - 2*dy*py*r**2 -
2*dz*pz*r**2 + 2*dx*qx*r**2 + 2*dy*qy*r**2 + 2*dz*qz*r**2 +
sqrt((-2*cy**2*dx*px - 2*cz**2*dx*px + 2*cx*cy*dy*px + 2*cx*cz*dz*px -
2*cy*dy*px**2 - 2*cz*dz*px**2 + 2*cx*cy*dx*py - 2*cx**2*dy*py -
2*cz**2*dy*py + 2*cy*cz*dz*py + 2*cy*dx*px*py + 2*cx*dy*px*py -
2*cx*dx*py**2 - 2*cz*dz*py**2 + 2*cx*cz*dx*pz + 2*cy*cz*dy*pz -
2*cx**2*dz*pz - 2*cy**2*dz*pz + 2*cz*dx*px*pz + 2*cx*dz*px*pz +
2*cz*dy*py*pz + 2*cy*dz*py*pz - 2*cx*dx*pz**2 - 2*cy*dy*pz**2 +
2*cy**2*dx*qx + 2*cz**2*dx*qx - 2*cx*cy*dy*qx - 2*cx*cz*dz*qx +
2*cy*dy*px*qx + 2*cz*dz*px*qx - 4*cy*dx*py*qx + 2*cx*dy*py*qx -
2*dy*px*py*qx + 2*dx*py**2*qx - 4*cz*dx*pz*qx + 2*cx*dz*pz*qx -
2*dz*px*pz*qx + 2*dx*pz**2*qx - 2*cx*cy*dx*qy + 2*cx**2*dy*qy +
2*cz**2*dy*qy - 2*cy*cz*dz*qy + 2*cy*dx*px*qy - 4*cx*dy*px*qy +
2*dy*px**2*qy + 2*cx*dx*py*qy + 2*cz*dz*py*qy - 2*dx*px*py*qy -
4*cz*dy*pz*qy + 2*cy*dz*pz*qy - 2*dz*py*pz*qy + 2*dy*pz**2*qy -
2*cx*cz*dx*qz - 2*cy*cz*dy*qz + 2*cx**2*dz*qz + 2*cy**2*dz*qz +
2*cz*dx*px*qz - 4*cx*dz*px*qz + 2*dz*px**2*qz + 2*cz*dy*py*qz -
4*cy*dz*py*qz + 2*dz*py**2*qz + 2*cx*dx*pz*qz + 2*cy*dy*pz*qz -
2*dx*px*pz*qz - 2*dy*py*pz*qz + 2*dx*px*r**2 + 2*dy*py*r**2 +
2*dz*pz*r**2 - 2*dx*qx*r**2 - 2*dy*qy*r**2 - 2*dz*qz*r**2)**2 -
4*(cy**2*dx**2 + cz**2*dx**2 - 2*cx*cy*dx*dy + cx**2*dy**2 +
cz**2*dy**2 - 2*cx*cz*dx*dz - 2*cy*cz*dy*dz + cx**2*dz**2 +
cy**2*dz**2 + 2*cy*dx*dy*px - 2*cx*dy**2*px + 2*cz*dx*dz*px -
2*cx*dz**2*px + dy**2*px**2 + dz**2*px**2 - 2*cy*dx**2*py +
2*cx*dx*dy*py + 2*cz*dy*dz*py - 2*cy*dz**2*py - 2*dx*dy*px*py +
dx**2*py**2 + dz**2*py**2 - 2*cz*dx**2*pz - 2*cz*dy**2*pz +
2*cx*dx*dz*pz + 2*cy*dy*dz*pz - 2*dx*dz*px*pz - 2*dy*dz*py*pz +
dx**2*pz**2 + dy**2*pz**2 - dx**2*r**2 - dy**2*r**2 - dz**2*r**2)*
(cy**2*px**2 + cz**2*px**2 - 2*cx*cy*px*py + cx**2*py**2 +
cz**2*py**2 - 2*cx*cz*px*pz - 2*cy*cz*py*pz + cx**2*pz**2 +
cy**2*pz**2 - 2*cy**2*px*qx - 2*cz**2*px*qx + 2*cx*cy*py*qx +
2*cy*px*py*qx - 2*cx*py**2*qx + 2*cx*cz*pz*qx + 2*cz*px*pz*qx -
2*cx*pz**2*qx + cy**2*qx**2 + cz**2*qx**2 - 2*cy*py*qx**2 +
py**2*qx**2 - 2*cz*pz*qx**2 + pz**2*qx**2 + 2*cx*cy*px*qy -
2*cy*px**2*qy - 2*cx**2*py*qy - 2*cz**2*py*qy + 2*cx*px*py*qy +
2*cy*cz*pz*qy + 2*cz*py*pz*qy - 2*cy*pz**2*qy - 2*cx*cy*qx*qy +
2*cy*px*qx*qy + 2*cx*py*qx*qy - 2*px*py*qx*qy + cx**2*qy**2 +
cz**2*qy**2 - 2*cx*px*qy**2 + px**2*qy**2 - 2*cz*pz*qy**2 +
pz**2*qy**2 + 2*cx*cz*px*qz - 2*cz*px**2*qz + 2*cy*cz*py*qz -
2*cz*py**2*qz - 2*cx**2*pz*qz - 2*cy**2*pz*qz + 2*cx*px*pz*qz +
2*cy*py*pz*qz - 2*cx*cz*qx*qz + 2*cz*px*qx*qz + 2*cx*pz*qx*qz -
2*px*pz*qx*qz - 2*cy*cz*qy*qz + 2*cz*py*qy*qz + 2*cy*pz*qy*qz -
2*py*pz*qy*qz + cx**2*qz**2 + cy**2*qz**2 - 2*cx*px*qz**2 +
px**2*qz**2 - 2*cy*py*qz**2 + py**2*qz**2 - px**2*r**2 -
py**2*r**2 - pz**2*r**2 + 2*px*qx*r**2 - qx**2*r**2 +
2*py*qy*r**2 - qy**2*r**2 + 2*pz*qz*r**2 - qz**2*r**2)))
/
(2*(cy**2*dx**2 + cz**2*dx**2 - 2*cx*cy*dx*dy + cx**2*dy**2 +
cz**2*dy**2 - 2*cx*cz*dx*dz - 2*cy*cz*dy*dz + cx**2*dz**2 +
cy**2*dz**2 + 2*cy*dx*dy*px - 2*cx*dy**2*px + 2*cz*dx*dz*px -
2*cx*dz**2*px + dy**2*px**2 + dz**2*px**2 - 2*cy*dx**2*py +
2*cx*dx*dy*py + 2*cz*dy*dz*py - 2*cy*dz**2*py - 2*dx*dy*px*py +
dx**2*py**2 + dz**2*py**2 - 2*cz*dx**2*pz - 2*cz*dy**2*pz +
2*cx*dx*dz*pz + 2*cy*dy*dz*pz - 2*dx*dz*px*pz - 2*dy*dz*py*pz +
dx**2*pz**2 + dy**2*pz**2 - dx**2*r**2 - dy**2*r**2 - dz**2*r**2))
One problem is that the formula actually isn't defined at $r$, which can be worked around by evaluating the function at some $r-\epsilon$. Maybe it's possible to rewrite the equation so that this limit problem isn't an issue, but I will not touch that. :P
I would insert the LaTeX formula in my post, but that would probably break something... I tried to make an image of the formula but my tools failed to create the resolution needed to get a crisp image (>30k wide image). In lieu of that here is a pdf version of the beautiful formula and even that required some work since LaTeX really doesn't like super wide equations.
// https://www.codechef.com/submit/complete/18917369
using namespace std; int main(){ int t; cin>>t; while(t--){ int n; cin>>n; int a[100]; int b[100]; for(int i=1;i<=n;i++){
cin>>a[i];
}
int d;//johnny position intial
cin>>d;
for(int i=1;i<=n;i++){
b[i]=a[i];
}
sort(a, a+n+1);
int m=b[d];
int count=0; for(int j=0;j<n;j++){ if(a[j]!=m){ count++; } else{ break; } }
cout<<count+1<<endl; } return 0;
}
my humble request to @admin to share test cases of contest problems with editorial, or provide feature to see test cases during submission after contest gets over..
while practicing one get WA, TLE or whatever error it must show testCases where code is failing similar to codeforces, hackerRank, hackerEarth etc. plateforms..
Reason is simple, during practice, when we try to upsolve contest problem, it will save our time to figure out what's wrong with our code
whenever we gets WA, then we try our best to figure out corner cases where code is failing, if succeed than its good
but if do not gets succeed than we post link to our submission on discuss, and we have to wait someOne will tell us corner case... most of times on codechef Discuss forum, someOne helps to figure out in which test case code is failing but someTimes we do not get replies...
if we know test cases, then we can figure out by ourselves where code is failing... and it will save our time to post "find where code is failing" type question on discuss and will also save others time of answering those questions..
i am facing this issue to figure out whats wrong with my june long challenge "TWOFL" problem
sorry for by bad English..
T = int(input()) for i in range(T) : A,B = list(map(int,input().split())) k = [] x=[] for i in range(1,100): if A%i==0 : k = k+ [i]
for i in range(1,100):
if B%i==0 :
x = x+ [i]
v=set(k)
w=set(x)
z=v.intersection(w)
p = max(z)
print(p)
Author:Teja Vardhan Reddy
Tester:Misha Chorniy
Editorialist:Bhuvnesh Jain
MEDIUM-HARD
Matrix Multiplication, Recurrences, Linearity of Expectation, Probabilities
You are given a circular which is equally divided into $H$ parts. There are $N$ building placed on the circle at some points, not necessarily distinct. You can start from any point and start shooting within a range of $X$. All building within the range collapse. You need to find the expected number of buildings which collapses when the probability of starting from any point is given by the following probability distribution:
$$a_i \text{is given for} 1 ≤ i ≤ K$$
$$a_i = \sum_{j=1}^{j=K} c_j\cdot a_{i-j} \quad \forall\,i:\;K \lt i \le h\,.$$
A simple brute force solution which first finds the probability of starting at each point and then simply iterates through each point and finds the number of buildings which are collapsed will work within the required constraints.
The time complexity of the above approach will be $O(H * K + N * H)$ as $X = H$ in the worst case. The first part is for the pre-computation and the next part if for finding the desired number of buildings which are collapsed. The space complexity is $O(H)$.
All the further subtasks require the knowledge of linearity of expectation and indicator random variables.
Let us define the indicator random variable $Y_i$. It equals $1$ if there is a building at position $i$ else $0$. Using this definition, the expected number of building which collapse is:
$$\text{Expected buildings} = \sum_{i=1}^{i=N} {a_i * \sum_{j=i}^{j=i+X} Y_j}$$
where the second sum is taken in a circular manner.
Using linearity of expectation (or rearrangement of terms), we can rewrite the above expression as:
$$\text{Expected buildings} = \sum_{i=1}^{i=N} {Y_i * \sum_{j=i-X}^{j=i} a[i]}$$
where the second sum is again taken in a circular manner.
Since $Y_i$ is defined to be $1$ for all points where buildings are present, we can see that outer sum runs for $O(N)$ times in worst case. For the inner sum, we can just maintain a prefix sum for array $a$ and thus find the required sum in $O(1)$.
Using this approach, the time complexity becomes $O(H * K + H + N)$ which is enough to pass this subtask. The space complexity is $O(H)$.
You can see editorialist approach for ${1}^{st}$ two subtasks below.
The last approach was bad as it required us to calculate the probability of starting at each point which is not possible as $H$ is very large. If carefully observed, the way future $a_i$ are generated is given by a recurrence relation. Don't confuse by seeing the convolution form in it. :(
In case you don't know how to solve recurrence using matrix multiplication, I suggest you go through this blog before.
In the last approach, we needed to calculate the prefix sum of some given range, for the recurrence relation, in an efficient manner. We can extend our matrix from $K * K$ for normal recurrence to include one extra row which will calculate the prefix sum. Below the idea with a recurrence containing 3 terms. We can generalise it later.
Let recurrence be $a_m = c_1 * a_{m-1} + c_2 * a_{m-2} + c_3 * a_{m-3}$. As per blog the matrix is given by
$$ \begin{bmatrix} c_1 & c_2 & c_3 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \end{bmatrix} \begin{bmatrix} a_{m-1} \\ a_{m-2} \\ a_{m-3} \end{bmatrix} = \begin{bmatrix} a_m \\ a_{m-1} \\ a_{m-2} \end{bmatrix} $$
To extend it to contain prefix sum as well, the matrix will look like:
$$ \begin{bmatrix} c_1 & c_2 & c_3 & 0 \\ 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ c1 & c2 & c3 & 1 \end{bmatrix} \begin{bmatrix} a_{m-1} \\ a_{m-2} \\ a_{m-3} \\ \sum_{i=1}^{i=m-1} a_i \end{bmatrix} = \begin{bmatrix} a_m \\ a_{m-1} \\ a_{m-2} \\ \sum_{i=1}^{i=m} a_i \end{bmatrix} $$
Got the idea, we basically store the initial prefix sum as the last value and add the current value to the prefix sum to extend it further. This can be easily extended to higher order recurrences as well.
Using the above idea naively, we can solve the problem in $O(N * K^3 * \log{H})$, where for every building we use matrix multiplication to calculate the prefix sums. This is enough to pass the ${3}^{rd}$ subtask but not the last one.
To solve the last subtask, we need to look at one important detail of matrix multiplication. Given matrices of sizes $(a, b)$ and $(b, c)$, the complexity for their multiplication is $O(a * b * c)$. We are used to using square size matrices, so we say the complexity is always cubic. In recurrences, the last step involves multiplying the recurrent matrix, $(K, K)$ with the base matrix, $(K, 1)$ which takes $O(K^2)$ complexity instead of $O(K^3)$. This gives us a neat optimisation as follows:
$${R}^{n} * B = R^{i_1} * ( \cdots * ({R}^{i_{\log{H}}} * B))$$
where $R$ is the recurrent matrix ($(K+1, K+1)$ matrix which is described above), $B$ is the base matrix ($(K+1, 1)$ matrix which is described above) and $n = 2^{i_1} + 2^{i_2} + \cdots + 2^{i_{\log{H}}}$.
An example of above equation is:
$${R}^{11} * B = R^1 * (R^2 * (R^8 * B))$$
Note that the above step now needs $O(K^2 * \log{H})$ complexity, reducing a factor $K$ from previous one. But we need to precompute the $2^w$ powers of the recurrent matrix. This can be done in $O(K^3 * \log{H})$.
Using the above ideas of precomputation and matrix multiplication, the complexity is $O(K^3 \log{H} + N * K^2 * \log{H})$. This will easily pass all the subtasks.
For more details, you can refer to the author's or tester's solution below.
The ideas of precomputation and matrix multiplication described above hold in the editorialist solution too.
The solution uses the following idea for finding the prefix sums or recurrence:
$$a_1 + a_2 + \cdots + a_m = R^0 * B + R^1 * B + \cdots + R^{(m-1)} * B = (R^0 + R^1 + \cdots + R^{(m-1)}) * B$$
So, we need to find the GP (Geometrix progression) sum of a matrix. This is a known problem. If you don't know about it, you can read similar problem here. But the only problem with this approach is the large constant factor involved. The matrix used to calculate the GP sum of a matrix is twice the size of given matrix, i.e. the matrix used will have size $(2k, 2k)$. Hence, a constant factor of $2^2 = 4$ is added to the complexity of the solution which is very hard to deal with. But with some neat observations like some parts of the matrix always retaining particular values, we can reduce the constant factor in the solution too.
I understand the above is a very brief idea of the solution, but in case you have any problem, you can read through the solution and ask any doubts you have in the comment section below.
The time complexity of the approach will be $O(4 * K^3 * \log{H} + 2 * N * K^2 * \log{H})$. The space complexity will be $O(4 * K^2)$.
Feel free to share your approach, if it was somewhat different.
Below is the general code used to calculate matrix multiplication in the modular field:
for i in [1, n]:
for j in [1, n]:
for k in [1, n]:
c[i][j] = (c[i][j] + a[i][k] * b[k][j]) % mod
It can be easily seen that above code uses $O(N^3)$ mod operations. It should be remembered that mod operations are costly operations as compared to simple operations like addition, subtraction, multiplication etc. We observe the following identity:
$$X \% \text{mod} = (X \% mod^2) \% \text{mod}$$
Above can be easily proved using $X = q * mod + r$. Using this fact, we can reduce the number of mod operations to $O(N^2)$ in matrix multiplication. Below is the pseudo-code for it:
mod2 = mod * mod
for i in [1, n]:
for j in [1, n]:
c[i][j] = 0
for k in [1, n]:
c[i][j] += a[i][k] * b[k][j] # Take care of overflows in interger multiplication.
if c[i][j] >= mod2:
c[i][j] -= mod2
c[i][j] %= mod
Note that above trick reduces the running time by approximately 0.8-0.9 seconds. Though it is not required for the complete solution, knowing it can always help and might be useful somewhere else.
$O(K^3 \log{H} + N * K^2 * \log{H})$
$O(K^3)$
Author's solution can be found here.
Editorialist's solution for subtask 1 and 2 can be found here.
Editorialist's solution can be found here.
https://www.codechef.com/problems/BOOKCHEF for this problem , i am getting a runtime error . Here's my code https://www.codechef.com/viewsolution/18917667
EASY MEDIUM
Binary Search, Greedy
N students are standing at distinct points in the X-axis. Every students will start running at t = 0. assign direction (left/right) to each of them such that the first time when any two students cross each other is as large as possible. Speed of every students is given.
Do binary search on the time. Suppose at any step in the binary search, we are are trying to find whether it is possible to assign direction such that no students will cross before some time say t.
To check, whether it is possible to assign direction. We fix the direction of leftmost students towards left (without loss of generality). For every other student from left to right, we try to fix the direction to left itself if it crosses non of the students before time t. And move to next student.
If it is not possible, we try to fix the direction as right. If it is possible then move to next student.
If we are able to assign direction to each students in that manner then the answer is yes, otherwise it is not possible.
For required precision, iterating 100 steps in the binary search is enough. Let's say the number of steps be S.
$O(S N)$ per test case.
$O(N)$
So due to some small mistake a while ago when my rating was dropped by around 500 points for plagiarism in a really old contest, I didnt say anything. I gave the June Long Challenge and to my surprise, despite having 500 points and a ranking of 71, I got an increase of just 200 points, while some other people of my college, some having solved only 2 questions got a boost of 175 points. Is there any basis behind this? What's the point of a lower rated person even solving the questions in long challenges then? Someone please look into this as I am not the only one pissed off by this.
While trying problems in short contest, most of you must be puzzled - where to start. Which is the easiest problem? Since initially the questions are sorted randomly and sometimes the 4th and 5th questions in the list come out to be the easiest. So it becomes pure luck which causes wastage of 5-10 minutes. Shouldn't we have an ordering of questions?
https://www.codechef.com/viewsolution/18918873 //
using namespace std; int main(){ int t; cin>>t; while(t--){ int n; cin>>n; int a[100]; int b[100]; for(int i=1;i<=n;i++){
cin>>a[i];
}
int d;//initial johnny position
cin>>d;
for(int i=1;i<=n;i++){
b[i]=a[i];
}
sort(a, a+n+1);
int m=b[d];
int count=0; for(int j=0;j<n;j++){ if(a[j]!=m){ count++; } else{ break; } }
cout<<count+1<<endl; } return 0;
}